L'entrepôt de données
Le data warehouse est le terme anglais qui veut dire entrepôt de données.
Selon
le grand dictionnaire une excellente référence qui nous donne accès à près de 3 millions de termes français et anglais du vocabulaire industriel, scientifique et commercial, dans 200 domaines d'activité :
Un entrepôt de données est une structure informatique dans laquelle est centralisé un volume important de données consolidées à partir des différentes sources de renseignements d'une entreprise (notamment les bases de données internes) et qui est conçue de manière que les personnes intéressées aient accès rapidement à l'information stratégique dont elles ont besoin.
En plus le grand dictionnaire précise dans le détail :
Si, dans le passé, l'entrepôt de données servait davantage à l'archivage, aujourd'hui il est devenu une pièce maîtresse de l'informatique décisionnelle (ou informatique d'aide à la décision). Il représente l'un des éléments essentiels d'un ensemble matériel et logiciel dynamique de recherche d'informations. Dans un entrepôt de données, les données sont : sélectionnées et préparées (pour répondre aux questions vitales de l'entreprise), intégrées (à partir des différentes sources de renseignements) et datées (elles gardent la trace de leur origine). Le terme entrepôt de données, employé très fréquemment, semble vouloir supplanter ses concurrents dépôt de données et centrale de données. Bien que le terme magasin de données soit utilisé comme équivalent de data warehouse par certains auteurs, il convient mieux au concept d'« operational data store ». D'après les renseignements inscrits dans la base de données IBMOT d'IBM, Information Warehouse est une marque de commerce d'International Business Machines Corp. Le terme lui-même est pourtant répertorié comme nom commun dans plus d'un dictionnaire unilingue anglais spécialisé.
Cette définition est tirée de celle de
Bill Inmon que l'on nomme le père des entrepôts de données et l'inventeur de ce qu'on appelle EDW pour Entreprise Data warehouse ou CIF pour Corporate Information Factory . Voici la définition de Bill Inmon (traduit par
Comment ça marche ) :
Le datawarehouse est orienté sujets, cela signifie que les données collectées doivent être orientées « métier » et donc triées par thème;
Le datawarehouse est composé de données intégrées, c'est-à-dire qu'un « nettoyage » préalable des données est nécessaire dans un souci de rationnalisation et de normalisation;
Les données du datawarehouse sont non volatiles ce qui signifie qu'une donnée entrée dans l'entrepôt l'est pour de bon et n'a pas vocation à être supprimée ;
Les données du datawarehouse doivent être historisées, donc datées.
Selon moi ce qu'il faut retenir, c'est que l'entrepôt de données est avant tout un emplacement de stockage de données afin de pouvoir y accéder pour l'analyse et la prise de décision. Il est donc à ne pas confondre avec la Business intelligence.
Le modèle dimensionnel de données
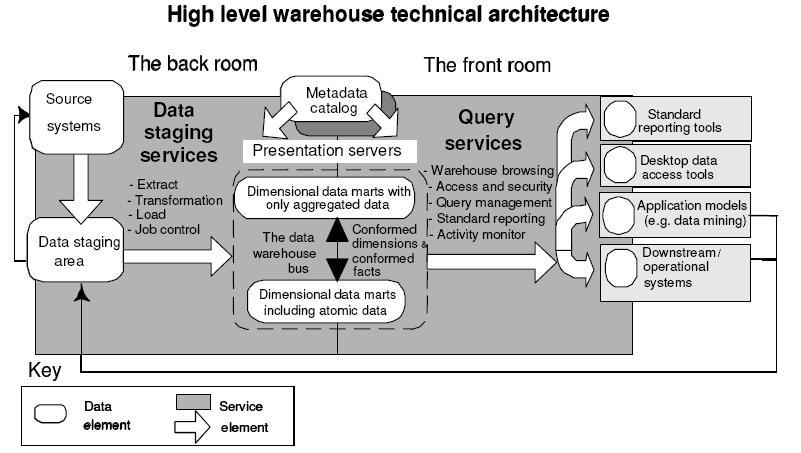
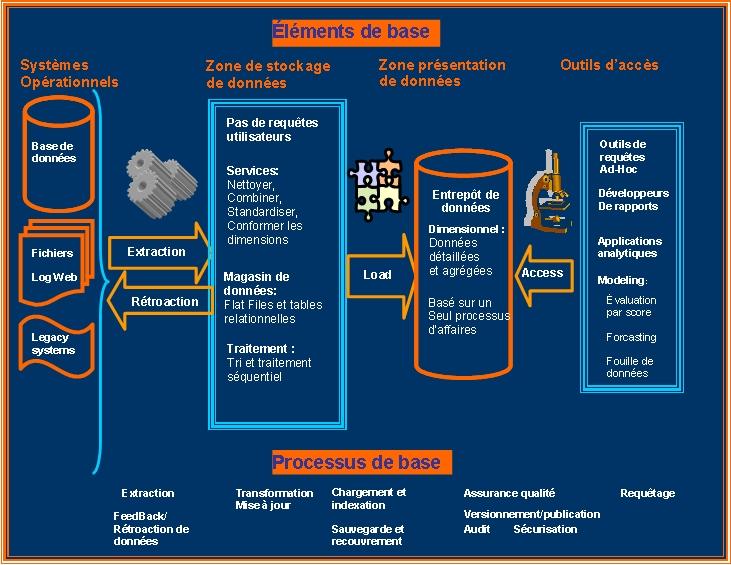
Avant de commencer à développer des systèmes ETL, il est important de bien maîtriser un certain nombre de notions, concepts et mécanismes. Nous commençons cette liste par le modèle dimensionnel.
En effet, les structures de données dimensionnelles sont la destination des processus ETL et ces tables se positionnent à la frontière entre le Back Room et le Front Room. En général les tables dimensionnelles sont l'étape finale de stockage physique de données avant leur transfert vers l'environnement des utilisateurs finaux.
Nous faisons ici un petit rappel du modèle dimensionnel :
Il s'agit de la structure de données la plus utilisée et la plus appropriée aux requêtes et analyses des utilisateurs. Elles sont simples à créer, stables et intuitivement compréhensibles par les utilisateurs finaux.
Le modèle dimensionnel est la fondation même pour la construction des cubes OLAP.
Nous introduisons alors les deux structures de données les plus rudimentaires du modèle dimensionnel : table de fait et table de dimension.
Table de fait :
table qui contient les données observables (les faits) que l'on possède sur un sujet et que l'on veut étudier, selon divers axes d'analyse (les dimensions).
les « faits », dans un entrepôt de données, sont normalement numériques, puisque d'ordre quantitatif. Il peut s'agir du montant en argent des ventes, du nombre d'unités vendues d'un produit, etc.
Table de dimension :
table qui contient les axes d'analyse (les dimensions) selon lesquels on veut étudier des données observables (les faits) qui, soumises à une analyse multidimensionnelle, donnent aux utilisateurs des renseignements nécessaires à la prise de décision.
On appelle « dimension » un axe d'analyse. Il peut s'agir des clients ou des produits d'une entreprise, d'une période de temps comme un exercice financier, des activités menées au sein d'une société, etc.
Le modèle dimensionel :
La figure suivante représente un exemple de schéma en étoile, le schéma qui est le plus adapté à la modélisation dimensionnelle. Dans cette exemple l'analyse des ventes ( table de fait des ventes) est effectuée selon les quatres axes que représentent les dimensions du schéma, à savoir les clients, les produit, le temps et les vendeurs. Un exemple du genre de question à laquelle nous serons capable de répondre en utilisant ce modèle est : "Quel le montant des ventes du produit P par le vendeur V au client C lors du mois M ?"
Qualité de données
Une donnée de qualité est une donneé exacte et précise donc :
Correcte : les valeurs et les descriptions décrivent d’une façon véridique et fidèle les objets qu’elles représentent. Par exemple le nom de la ville dans laquelle un client vit actuellement s’appelle Montréal. Donc, la valeur de la donnée sur la ville du client doit être Montréal pour être correcte.
Non ambiguë : les valeurs et les descriptions doivent avoir une seule signification. Par exemple, il existe n villes dans le monde dont le nom est Casablanca, cependant il en existe seulement une au Maroc. Par conséquent dans le but qu’une adresse soit précise et non ambiguë, il faut que celle-ci contienne et le nom de la ville, Casablanca, et le nom du Pays.
Consistante : Les valeurs et des descriptions utilisent une convention de nomenclature unique. Par exemple la province du Québec est parfois écrite Qc, PQ,… Pour être consistant il faut utiliser une seule convention de nomenclature.
Complète : Il existe deux aspects de la complétude :
o IL faut s’assurer que chaque donnée obligatoire contient une valeur.
o Il faut s’assurer, en transformant les données, de ne pas perdre des valeurs ou des enregistrements.
L'OLAP
En 1993, E.F Codd (1923-2003), l'inventeur des bases de données relationnelles, & associés ont publié un document de présentation technique à la demande de la compagnie Arbor Software, devenue aujourd'hui Hyperion, sous le titre 'Providing OLAP (On-Line Analytical Processing) to User-Analysts : An IT Mandate'.
Du fait que ce document soit commandité par une compagnie privée, les règles OLAP telles que définies par E.F Codd étaient contreversées.
Ceci nous donne un peu d'histoire sur les origines du terme OLAP.
Revenons maintenant au terme OLAP, Mr. Nigel Pendse (
www.olapreport.com/fasmi.htm) persiste et signe que (traduction libre de son texte) :
Ce terme ne donne ni une définition ni une description claire de ce que signifie OLAP. Il ne donne non plus aucune indication pourquoi utiliser un outil OLAP, ni si tel outil en est un outil OLAP.
Personnellement, je ne crois pas qu'a partir d'un acronyme ou du nom d'un outil ou d'une technique on serait capable de déduire la définition, la description, l'utilisation... d'un tel outil ou technique. Prenons par exemple DataBase, tout ce qu'on peut comprendre d'un tel terme c'est qu'il s'agit d'un endroit ou l'on stocke les données, cela ne nous donne pas forcément une description de ce que c'est une base de données, ni si Excel est une base de données ou pas !
Cependant, l'auteur (Nigel Pendse) , recapitule la définition de l'OLAP en cinq mot : Fast Analysis of Shared Multidimensional Information (FASMI) traduit en français par
http://www.linux-france.org/prj/jargonf/F/FASMI.html comme suit : « Analyse Rapide d'Information Multidimensionnelle Partagée ».
Ce qui attire mon attention dans cette définition c'est la limitation de l'OLAP au modèle Multidimensionel, alors dans la définition OLAP, en tant que On-Line Analytic Processing, aucune limite tant qu'a la modélisation des données n'est imposée. Certes actuellement la représentation la plus utilisée est le multidimensionnel, cependant dans le future ne serait-il pas envisageable d'être obligé d'utiliser autre sorte de représentation ?
Copyright © Abdel ELOMARI 2005-2006 . Tous droits réservés.