 Les composantes et processus ETL
Les composantes et processus ETLComme nous l'avons déjà mentionné, un système décisionnel est formé de deux principales composantes le Back Room et le Front Room.
Le Back room ou encore la zone de préparation de données réalise les services suivants :
- l'extraction des données à partir des systèmes sources;
- la transformation des données ( Normalisation, standards, nettoyage, audit, Conformance...) ;
- le chargement des données que ce soit dans un DW ou dans un Data Mart; - Un service qui est plus au moins récent qui est celui de fournir de l'information aux systèmes sources ( Exemple : Selon les analyses d'habitudes d'achats effectuées dans l'entrepôt de données on communique à des systèmes temps-réels des informations utiles pour afficher des bannières de publicités qui sont susceptibles d'interesser un client en particulier... La technique utilisée pour stocker l'expérience d'achat s'appelle le Click-Stream...)
Le Front room est la composante qui permet de réaliser des services comme :
- L'analyse de données via des rapports ou des cubes (OLAP, Report ADhoc,...) ;
- le forage et l'exploration de données en utilisant des outils spécialisés ( SPPS, SAS...) ;
- les requêtes ADhoc pour retrouver une données dans le passé parmi les données historisées ( Le rôle le plus vieux d'un système décisionnel)
Cependant il ne faut pas limiter l'utilisation des outils ETL à l'alimentation des entrepôts de données, car un système ETL pourrait bien être utilisé pour intégrer les données d'applications réparties ou encore centraliser les données de différents systèmes dans une seule bases de données...
Dans la figure suivante, nous proposons une architecture qui met en évidence les deux composantes et les services fournis par chacune de ces dernières :
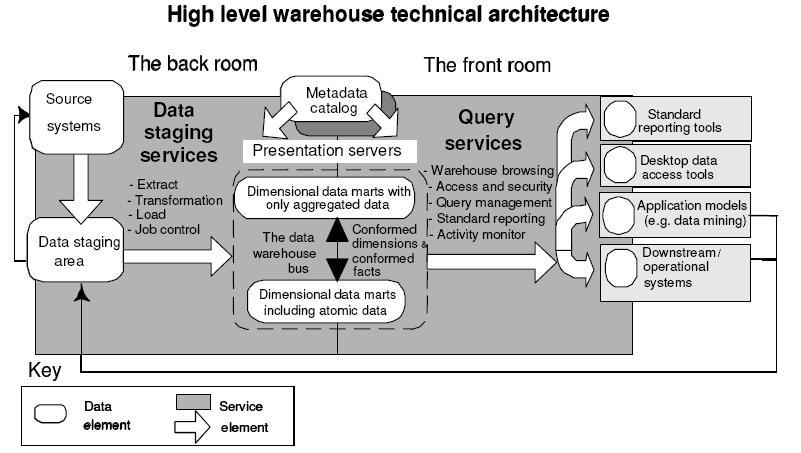
Figure : Architecture générale d'une solution décisionnelle.
La figure suivante présente, en plus des éléments de bases d'une solution décisionnelle, les processus élémentaires de traitement :
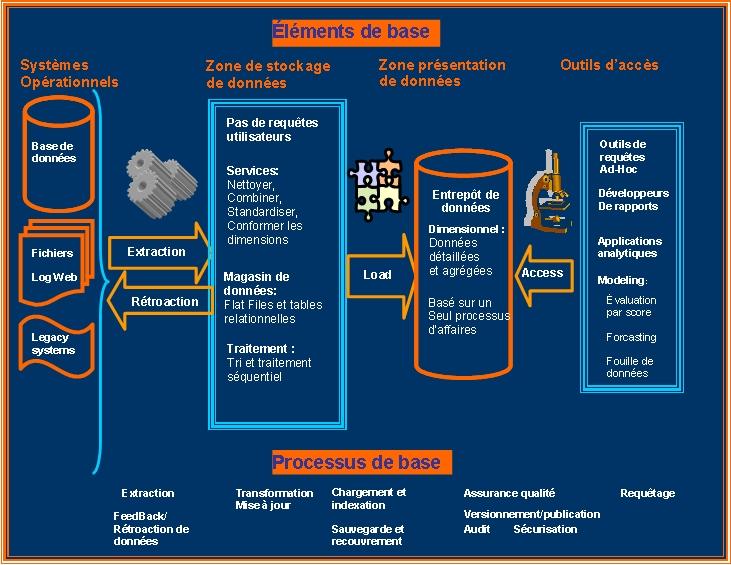
Figure : Eléments et processus de base d'une solution décisionnelle.
Voici une explication de chaque élément et de chaque processus :
Les systèmes opérationnels
En général les entrepôts de données sont alimentés à partir de systèmes opérationnels dans le but de transformer les données transactionnelles ( Ou opérationnelles ) d'un processus d'affaire en information qui sera utile à la prise de décision. Cependant il faut bien noter que les entrepôts de données peuvent aussi puiser leurs données dans d'autres entrepôts de données, dans un ODS, ERP ou CRM. Prenons un exemple pour mieux comprendre le besoin d'extraire les données d'un système CRM : dans chaque entrepôt de données il est fort probable qu'une table des clients existe. Dans un but d'intégration il n'est pas question de disposer de cette table autant de fois qu'il y'a d'applications dans l'entreprise. Normalement, une seule application CRM permet de gérer cette table et de fournir au autres applications une vue de cette table. Évidement on peut imaginer toute sorte de mécanisme ( Réplication , Snapshot...) pour que ces applications disposent de cette table à jour. Dans le même sens il est donc conseillé dans la cas de l'entrepôt de données d'extraire cette table du système CRM au lieu de l'extraire du système opérationnel du processus que l'on veux analyser ou étudier.
Il existe plusieurs strutures de données dans ces systèmes opérationnels, les données que l'on désire extraire peuvent donc résider dans une base de données, dans des fichiers plats, ou encore dans des systèmes patrimoniaux ( Legacy systems). On peut aussi extraire les données à partir des fichiers log du Web dans le cas des entrepôts de données d'analyse des click-stream...
Il existe plusieurs strutures de données dans ces systèmes opérationnels, les données que l'on désire extraire peuvent donc résider dans une base de données, dans des fichiers plats, ou encore dans des systèmes patrimoniaux ( Legacy systems). On peut aussi extraire les données à partir des fichiers log du Web dans le cas des entrepôts de données d'analyse des click-stream...
Extraction
L'extraction des données est la première étape dans les systèmes ETL. Elle permet de lire les données à partir des systèmes sources. Selon la nature de ces systèmes sources ( 24/7, critique...) l'extraction peut s'avérer critique et très exigeante dans le sens ou il faut la réaliser le plus rapidement souvent et ce en exploitant au minimum les ressources du système source. En général les extractions sont lancées la nuit durant ce l'on appelle un Extract Window sur lequel on s'est mis d'accord. La complexité de l'extraction n'est pas dans le processus de lecture, mais surtout dans le respect de l'extract window. C'est pour cette raison que l'on effectue rarement des transformations lors de l'extraction d'une part. D'autre part, on essaye au maximum d'extraire seulement les données utiles ( Mise à jour ou ajoutée aprés la dernière extraction) et pour ce faire on pourrait s'entendre avec le responsable du système source pour ajouter soit un flag ou encore des dates dans chacune des tables extraites, au moins deux dates : Date de création de l'enregistrement dans la table et la date de mise à jour ( En général la plupart des systèmes sources disposent de ces deux dates ) . Par ailleurs pour ne pas perdre des données suites à des problèmes d'extraction, il est important de s'assurer que le système source ne purge pas les données avant que l'entrepôt ne les aies extraits.
Transformation
La transformation est la tâche la plus complexe et qui demande beaucoup de reflexion. Voici les grandes fonctionalités de transformation :
- Néttoyage des données
- Standardisation des données.
- Conformance des données.
... à venir
- Néttoyage des données
- Standardisation des données.
- Conformance des données.
... à venir
Chargement
Cette fonctionalité des systèmes ETL est une source de beaucoup de confusion, selon la situation elle permet :
1) de charger les données dans l'entrepôt de données qui est théoriquement la destination ultime des données ;
2) ou de les charger dans des cubes de données.
La réponse est différente selon le choix de votre solution BI :
- Si vous avez choisi de batir des datamarts, et de ne pas stager (Donc pas de DW comme tel) les données nous pouvons considèrer la deuxième option. Il est donc question de charger les données directement dans des cubes de données sans les stocker dans un DW. Cette approche est certainement la plus proche à celle de Ralph Kimball. Un bon exemple est l'utilisation direct des cubes de données cognos.
- Si vous avez choisi de construire un entrepôt de données avec une base de données, alors la destination ultime des données est l'entrepôt. Donc le Chargement permet de stocker ces données dans un entrepôt de données. Cette approche est proche à celle de Bill Inmon. Vous pouvez alors utiliser des focntionalités analytiques comme Oracle le permet.
- Une troisième option est c'est celle que je préconise et qui offre plusieurs avantages mais demande par contre plus d'effort. Le chargement des données se fait en deux étapes :
1) de charger les données dans l'entrepôt de données qui est théoriquement la destination ultime des données ;
2) ou de les charger dans des cubes de données.
La réponse est différente selon le choix de votre solution BI :
- Si vous avez choisi de batir des datamarts, et de ne pas stager (Donc pas de DW comme tel) les données nous pouvons considèrer la deuxième option. Il est donc question de charger les données directement dans des cubes de données sans les stocker dans un DW. Cette approche est certainement la plus proche à celle de Ralph Kimball. Un bon exemple est l'utilisation direct des cubes de données cognos.
- Si vous avez choisi de construire un entrepôt de données avec une base de données, alors la destination ultime des données est l'entrepôt. Donc le Chargement permet de stocker ces données dans un entrepôt de données. Cette approche est proche à celle de Bill Inmon. Vous pouvez alors utiliser des focntionalités analytiques comme Oracle le permet.
- Une troisième option est c'est celle que je préconise et qui offre plusieurs avantages mais demande par contre plus d'effort. Le chargement des données se fait en deux étapes :
- Un premier chargement des données dans un entrepôt de données.
- Un deuxième chargement dans des cubes de données.
- La possibilité de rechargement des cubes, parceque les données sont stockées dans une base de données de l'entrepôt de données.
- La possibilité de garder les faits et les dimensions dans leur détail de grain le plus fin.
- La possibilité de créer des agrégats...
- Plus de flexibilité à retraiter les données, les corriger, appliquer des redressements autorisés par les gens d'affaires, tâches qui ne sont pas facile dans un médium de stockage dimensionnel. ( Je ne sais pas comment on peut retoucher les données déjà stockées dans un cube Powerplay...);
- Ne pas avoir à charger le détail dans les cubes (Certains cubent représentent plusieurs limitations dans ce sens, il n'est donc pas facile de charger une grande quantité de données dans un Cube). On utilise les cubes pour les analyses de plus haut niveau, et quant il est question d'accèder au détail le plus fin de l'information on fait une lecture dans la BD de l'entrepôt de données.
- Une base de données à créer et à maintenir, donc un DBA et un ADD.
- Un exercice de reflexion sur le modèle de données du DW ( En général ROLAP).
- Un autre excercie de reflexion sur le modèle des métadonnées (En général MOLAP)
feedback
Le feedback concerne les deux aspects suivants :
- Informer le système source du résultat de l'extraction : réussite, échec, date dernière extraction, date prochaine extraction...
- Transmettre de l'information aux systèmes sources ( parfois aussi à l'ODS). L'exemple le plus citée est celui lorsque l'entrepôt de données aprés analyse des click-streams de l'expérience de navigation d'un client (Que l'on reconnait par son adresse IP) renvoit de l'information aux systèmes opérationnels dans le but d'afficher les bannières les plus appropriées !!
Copyright © Abdel ELOMARI 2005-2006 . Tous droits réservés.
- Informer le système source du résultat de l'extraction : réussite, échec, date dernière extraction, date prochaine extraction...
- Transmettre de l'information aux systèmes sources ( parfois aussi à l'ODS). L'exemple le plus citée est celui lorsque l'entrepôt de données aprés analyse des click-streams de l'expérience de navigation d'un client (Que l'on reconnait par son adresse IP) renvoit de l'information aux systèmes opérationnels dans le but d'afficher les bannières les plus appropriées !!
Copyright © Abdel ELOMARI 2005-2006 . Tous droits réservés.
Aucun commentaire:
Publier un commentaire